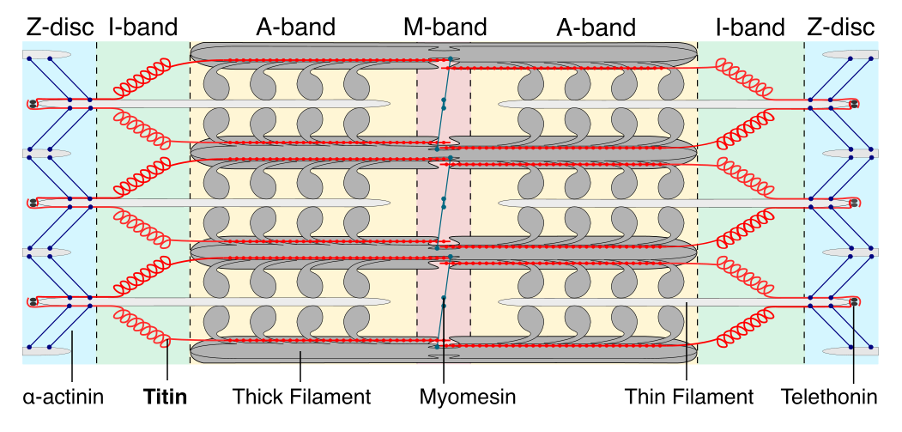
The giant sarcomeric protein titin is the largest protein in the body: each individual titin molecule spans half a muscle sarcomere in length, with the longest inferred complete (IC) isoform consisting of 35991 amino acids. Moreover, titin is known to be an important disease gene, with variants associated with both cardiac myopathies, particularly dilated cardiomyopathy (DCM), and skeletal myopathies collectively known as "titinopathies".
TITINdb is a web application originally developed to integrate titin structure, sequence, isoform, variant and disease information in a single location, with a focus on missense variants (defined as non-synonymous single nucleotide variations (nsSNVs) which result in single amino acid variations (SAVs), excluding nonsense and synonymous variations). In total TITINdb2 contains 48,288 individual missense variants, including both population nsSNVs from the 1000 Genomes Project and gnomAD databases, and 76 SAVs reported as damaging in the scientific literature. Each variant is annotated with features including predicted solvent accessibility, RefSeq dbSNP reference SNP identifier (rsid), and a wide range of variant impact predictions from commonly used bioinformatics tools (see Documentation), which may be selected or omitted at will using the new Custom Data Table dialog option.
The titin protein is modular in structure, and consists primarily of globular Ig and Fn3 domains as well as a single kinase domain. TITINdb2 provides the ability for users to easily visualise selected variants on domain-level protein structures, using experimentally derived PDB structures where available, and predicted structural models computed by AlphaFold2 where not. Domain boundaries are defined according to titin sequence and experimental information (see Documentation for more details), and all positions in the titin protein have been mapped to the seven major isoforms (IC, N2AB, N2B, N2A, novex-1, novex-2, novex-3) in protein, transcript and genomic coordinates. Users may easily translate between isoforms when searching by position, and the newly implemented Variant Converter allows for variants to be freely converted between different coordinate systems in bulk.
TITINdb2 supports the following options for querying the database:
All structures and data can be downloaded from the Downloads page, while individual structure pages allow for PDB data and SAV data tables to be downloaded for that system only.
When using this tool in publication, please cite Weston, T., Ng, J., Gracia Carmona, O., Gautel, M., & Fraternali, F. (2025). TITINdb2—expanding annotation and structural information for protein variants in the giant sarcomeric protein titin. Bioinformatics Advances, 5(1). Laddach, A., M. Gautel and F. Fraternali (2017). "TITINdb-a computational tool to assess titin's role as a disease gene." Bioinformatics 33(21): 3482-3485.
Any comments or suggestions are welcomed.